![]()
FAIRDOM-SEEK is an open source web-based cataloguing and commons platform, for sharing heterogeneous scientific research datasets, models or simulations, processes and research outcomes. It preserves associations between them, along with information about the people and organisations.
Underpinning FAIRDOM-SEEK is the ISA infrastructure, a standard framework for describing how individual experiments are aggregated into wider studies and investigations. Within FAIRDOM-SEEK, ISA has been extended and is configurable to allow the structure to be used outside of Biology.
Flexible and detailed sharing permissions are available to manage the catalogued items from early collaborations within projects, through to the publishing of final research results. At this point a DOI can be generated for individual items, or entire aggregates packaged as Research Objects
FAIRDOM-SEEK incorporates semantic technology, allowing sophisticated queries over the content. Metadata can be collected using standard Excel tools and processes, through the use of RightField.
A publicly available instance of a FAIRDOM-SEEK commons is available - as the FAIRDOMHub.
![]()
Organise and store data
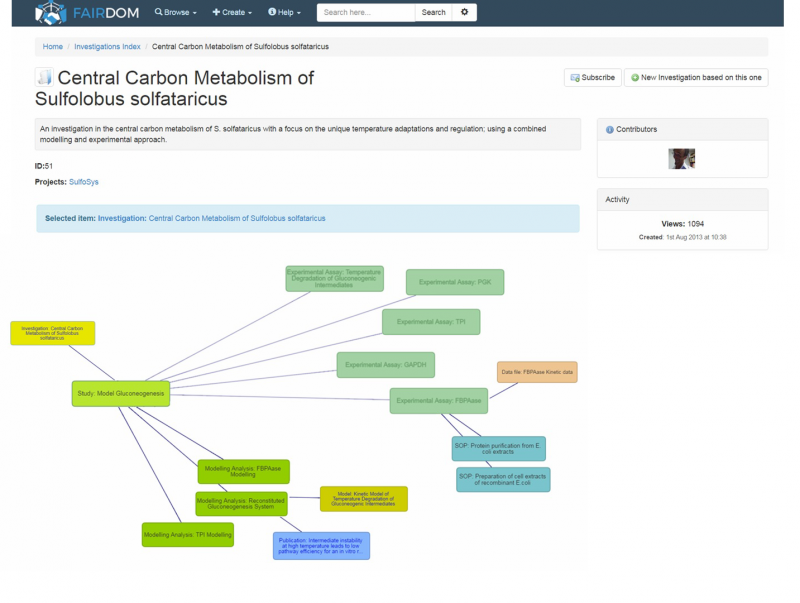
FAIRDOM-SEEK has adopted an ISATAB style structure for organising experiments and data.
Explore and annotate data
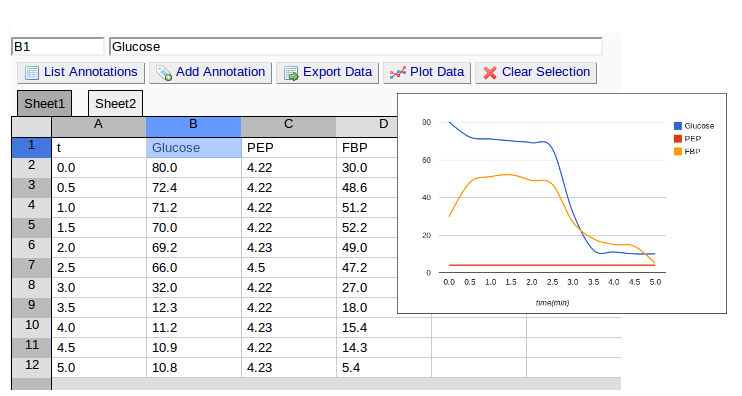
Excel spreadsheets can be explored and annotated without the need to download.
Simulate SBML models
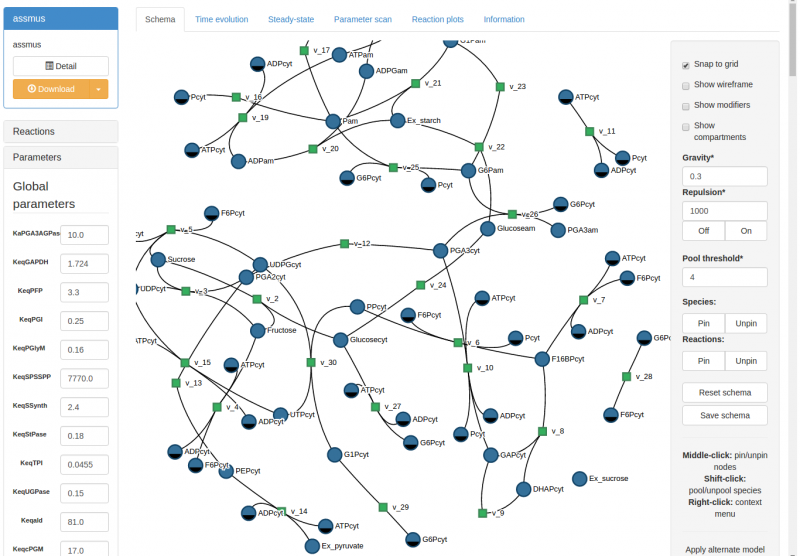
Most models that conforms to the SBML format can be simulated within FAIRDOM-SEEK.
Who is doing what, where?
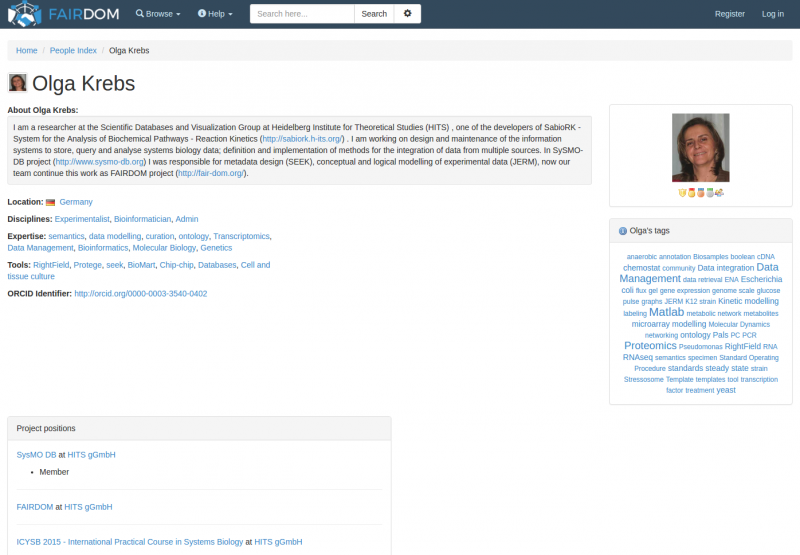
We recognise that people, and their knowledge, are important.
Flexible sharing controls
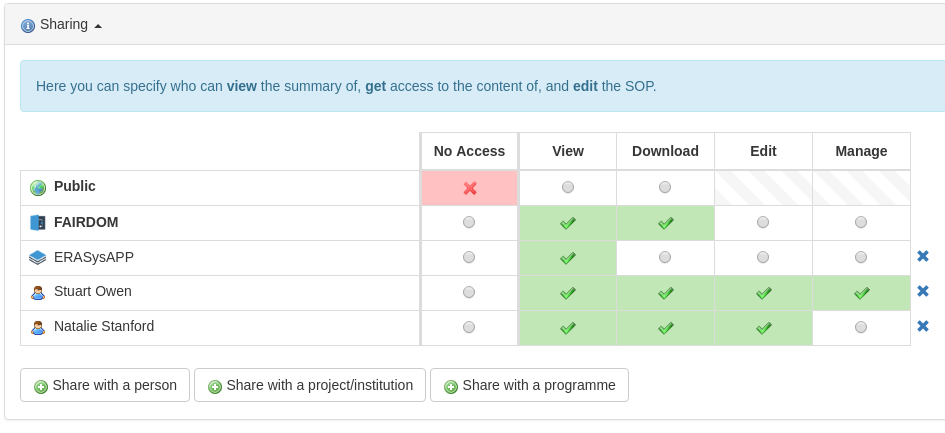
There is a lot of flexibility and control over who can see, download or edit your items.
Semantic templates
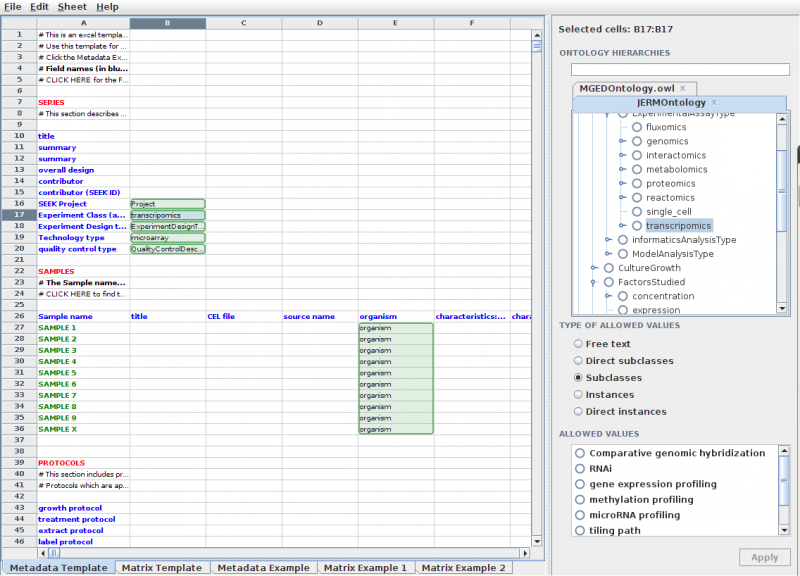
RightField enabled sheets allow rich semantic descriptions of data. Our Just Enough Results Model can be used with Rightfield.